Raft源码分析(三) - commit提交状态跟踪
lastApplied & commitIndex & latLogIndex 示意图
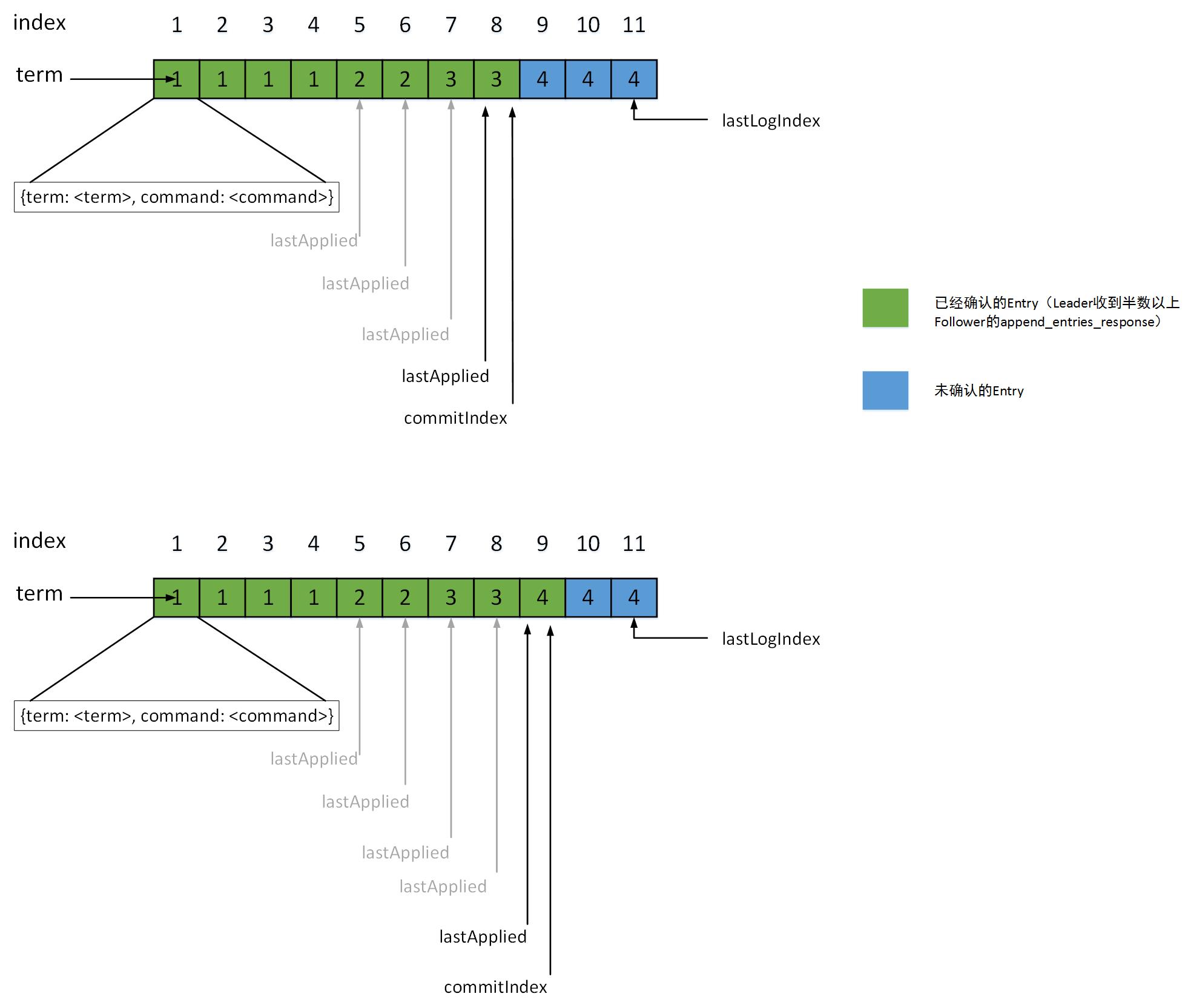
上图中,上半部分说明lastApplied会根据commitIndex,自动追平。当 Leader 中的 index 为 9 的 entry,完成半
数以上replication后,commitIndex := 9,同时,lastApplied还是会自动追平。下面源码中会详细分析。
以下是lastApplied、commitIndex的定义:
storage.py
class Log:
"""Persistent Raft Log on a disk
Log entries:
{term: <term>, command: <command>}
{term: <term>, command: <command>}
...
{term: <term>, command: <command>}
Entry index is a corresponding line number
"""
UPDATE_CACHE_EVERY = 5
def __init__(self, node_id, serializer=None):
self.filename = os.path.join(config.log_path, '{}.log'.format(node_id.replace(':', '_')))
os.makedirs(os.path.dirname(self.filename), exist_ok=True)
open(self.filename, 'a').close()
self.serializer = serializer or config.serializer
self.cache = self.read()
# All States
# commit_index、last_applied在所有Role角色中均会使用到,分析后得知,目前只有Leader/Follower才会使用到,
# 其实 Candidate 只是在election时才会用到,是一个临时跳板角色
"""Volatile state on all servers: index of highest log entry known to be committed
(initialized to 0, increases monotonically)"""
self.commit_index = 0
"""Volatile state on all servers: index of highest log entry applied to state machine
(initialized to 0, increases monotonically)"""
self.last_applied = 0
# Leaders
# next_index仅在Leader中使用,记录Follower中的下一个entry的index位置,即append_entries_response中Follower的last_log_index + 1
"""Volatile state on Leaders: for each server, index of the next log entry to send to that server
(initialized to leader last log index + 1)
{<follower>: index, ...}
"""
self.next_index = None
"""Volatile state on Leaders: for each server, index of highest log entry known to be replicated on server
(initialized to 0, increases monotonically)
{<follower>: index, ...}
"""
# match_index仅在Leader中使用,记录Follower中已经replication完成的entry index
self.match_index = None
lastApplied更新逻辑
state.py
def validate_commit_index(func):
"""Apply to State Machine everything up to commit index"""
@functools.wraps(func)
def wrapped(self, *args, **kwargs):
# LIUHAO: Attention here, [log.last_applied, log.commit_index) but not 'log.last_log_index'
# 这里根据commit_index,last_applied自动追平
for not_applied in range(self.log.last_applied + 1, self.log.commit_index + 1):
self.state_machine.apply(self.log[not_applied]['command'])
self.log.last_applied += 1
try:
# LIUHAO: In concurrent requests case, how to make Future can reply Client's execute_command call correctly???
# 疑点:
# self.apply_future 是 Leader.execute_command 中异步等待的变量,在并发情况下,如何保证 apply_future 的有序性呢?
self.apply_future.set_result(not_applied)
except (asyncio.futures.InvalidStateError, AttributeError):
pass
return func(self, *args, **kwargs)
return wrapped
Leader 中 commitIndex源码分析
state.py
class Leader(BaseRole):
...
def update_commit_index(self):
'''
LIUHAO: Update commit_index of leader when Leader receives responses from Follower
'''
commited_on_majority = 0
# 在当前[commit_index+1, last_log_index + 1)范围内遍历,Leader中的 index 已得到 match_index 半数以
# 上 Follower 回应,并且,log[index]['term'] 与最新 storage.term 相同时,更新 commit_index
for index in range(self.log.commit_index + 1, self.log.last_log_index + 1):
commited_count = len([
1 for follower in self.log.match_index
if self.log.match_index[follower] >= index
])
# If index is matched on at least half + self for current term — commit
# That may cause commit fails upon restart with stale logs
is_current_term = self.log[index]['term'] == self.storage.term
if self.state.is_majority(commited_count + 1) and is_current_term:
commited_on_majority = index
else:
break
if commited_on_majority > self.log.commit_index:
self.log.commit_index = commited_on_majority
那 match_index 是什么时候更新的?来看一下 Leader.on_receive_append_entries_response 方法:
@validate_commit_index
@validate_term
def on_receive_append_entries_response(self, data):
sender_id = self.state.get_sender_id(data['sender'])
# Count all unqiue responses per particular heartbeat interval
# and step down via <step_down_timer> if leader doesn't get majority of responses for
# <step_down_missed_heartbeats> heartbeats
if data['request_id'] in self.response_map:
self.response_map[data['request_id']].add(sender_id)
if self.state.is_majority(len(self.response_map[data['request_id']]) + 1):
self.step_down_timer.reset()
del self.response_map[data['request_id']]
if not data['success']:
# LIUHAO: next_index is descreasing. Maybe in order to tolerant the follower to recover log data and catch up Leader
self.log.next_index[sender_id] = max(self.log.next_index[sender_id] - 1, 1)
else:
# LIUHAO: Trace next_index, match_index for follower inside Leader.
# append_entries 成功时,
# next_index[follower_id] 更新为Follower的last_log_index+1,
# match_index[follower_id]更新为Follower的last_log_index
self.log.next_index[sender_id] = data['last_log_index'] + 1
self.log.match_index[sender_id] = data['last_log_index']
# 更新commit_index
self.update_commit_index()
# Send AppendEntries RPC to continue updating fast-forward log (data['success'] == False)
# or in case there are new entries to sync (data['success'] == data['updated'] == True)
if self.log.last_log_index >= self.log.next_index[sender_id]:
# LIUHAO: Continue to send data to the follower
asyncio.ensure_future(self.append_entries(destination=sender_id), loop=self.loop)
Follower 中commitIndex源码分析
state.py
class Follower(BaseRole):
...
@validate_commit_index
@validate_term
def on_receive_append_entries(self, data):
self.state.set_leader(data['leader_id'])
# Reply False if log doesn’t contain an entry at prev_log_index whose term matches prev_log_term
try:
prev_log_index = data['prev_log_index']
# 检查Leader侧提供的Follower的prev_log_index、Leader的term,与本地相比,是否有效
# 如果无效,则直接返回 False
# 注意:
# raft白皮书有提到,无效时,可以携带Follower的 last_log_index,给到 Leader 侧,这样做可以使
# Leader 侧快速定位 Follower 的 next_index,进而减少Leader侧无效的 append_entries 通信次数
if prev_log_index > self.log.last_log_index or (
prev_log_index and self.log[prev_log_index]['term'] != data['prev_log_term']
):
response = {
'type': 'append_entries_response',
'term': self.storage.term,
'success': False,
'request_id': data['request_id']
}
# 异步回应Leader
asyncio.ensure_future(self.state.send(response, data['sender']), loop=self.loop)
return
except IndexError:
pass
# If an existing entry conflicts with a new one (same index but different terms),
# delete the existing entry and all that follow it
# 将Leader发过来的entries数据,存至Log中 new_index 开始的位置
new_index = data['prev_log_index'] + 1
try:
# 有冲突时,直接擦除至尾部,向Leader看齐
if self.log[new_index]['term'] != data['term'] or (
self.log.last_log_index != prev_log_index
):
self.log.erase_from(new_index)
except IndexError:
pass
# LIUHAO: TODO
# 'log.write' will append entries to its tail. Should we reply Leader False message???
# It's always one entry for now
for entry in data['entries']:
self.log.write(entry['term'], entry['command'])
# Update commit index if necessary
# 注意这里的条件,Follower的commit_index 小于 Leader的commit_index时,才更新
# 问题:
# Follower的commit_index 大于 Leader的commit_index时,如何处理?
# 思考:
# 大于的情形有可能是 Follower 曾经是 Leader,commit_index 比较新 ,因为某些原因降级成 Follower。
# 但是,这种情形也不合理,因为 Leader 的 commit_index 只有收到过半Follower的 append_entries_response 后才会更新,
# 如此,Follower 的 commit_index 一定是小于 Leader 的 commit_index,直至 Leader 同步完最后一个 last_log_index
# 的 entry,Follower 的 commit_index 等于 Leader 的 commit_index(因为 Leader 的 update_commit_index 遍历范围
# [commit_index+1, last_log_index+1) 时 index 最大值为 last_log_index )。
if self.log.commit_index < data['commit_index']:
self.log.commit_index = min(data['commit_index'], self.log.last_log_index)
# Respond True since entry matching prev_log_index and prev_log_term was found
response = {
'type': 'append_entries_response',
'term': self.storage.term,
'success': True,
'last_log_index': self.log.last_log_index, # LIUHAO: Here, 'log.last_log_index' will be updated for that more than 1 entry be appended to the Log list
'request_id': data['request_id']
}
asyncio.ensure_future(self.state.send(response, data['sender']), loop=self.loop)
# 重置选举定时器
self.election_timer.reset()